Validating HTML
Via a retweet by Sara, I saw Dan Mall ask on Twitter:
Does anyone still validate their HTML?
To bluntly answer the question: I validate, but only when I encounter a perplexing cross-browser issue I can’t seem to solve.
In those cases, I’ll copy the one-off HTML document I’m dealing with and paste it into the W3C’s browser-based markup validation service to check for any errors I can’t seem to spot.
While that service is useful for manually validating individual documents, it’s not particularly practical for systematically validating HTML as part of an automated software development pipeline.
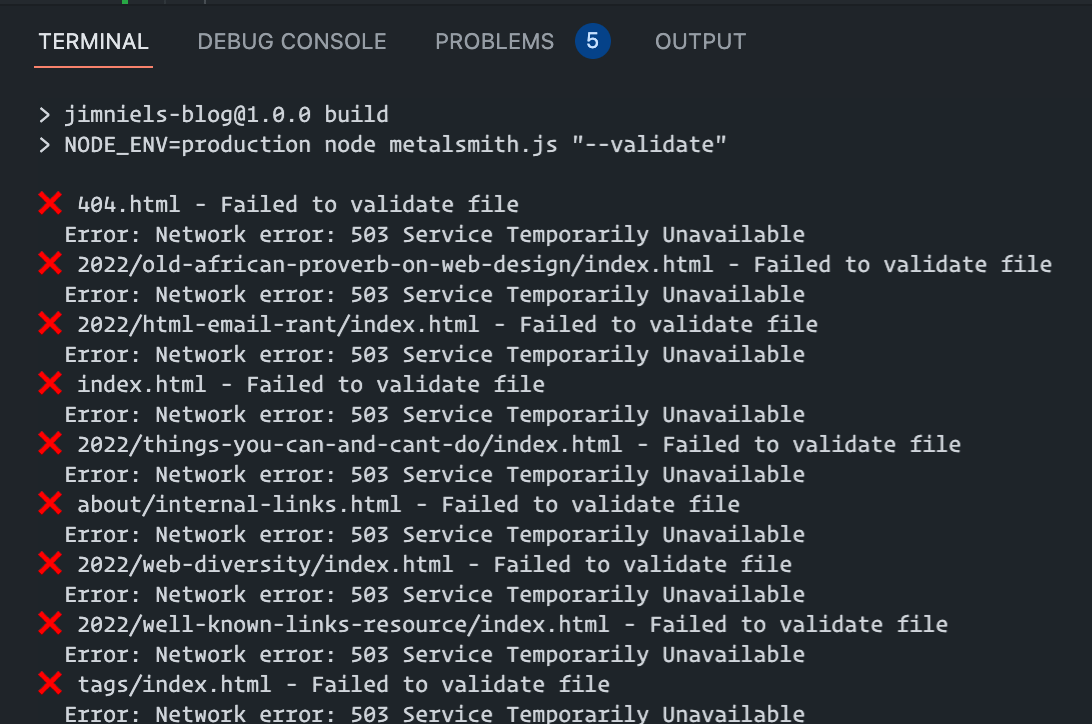
That said, a while back I discovered the W3C Nu HTML Checker which also validates HTML. It has a HTTP API which you can leverage to automate the process of validating multiple HTML documents.
I wrote a little script to interface with the API and check the HTML files output by my static site generator, but it kept returning 503 errors on many of the files.
I searched npm for a solution and, while I found many options, they all had one of the following self-imposed dealbreakers:
- Was a programatic abstraction on top of the Nu HTML Checker HTTP API, which I was already using and didn’t need somebody’s additional layer of abstraction.
- Was an old project with little usage, old commits, or some semblance of not being maintained.
- Required installing Docker or Java to run locally.
But did I give up? No. I went to Twitter:
What are people using to batch validate files? e.g. run your SSG, then feed all your
**/*.htmlfiles to some service that’ll validate your markup? I was using nu validator but getting lots of 503 errors when I do
I wasn’t necessarily expecting a service. I’d be more than happy with a CLI tool I could run locally as long as it didn’t require installing Java to do it.
Then, courtesy of @ffoodd_fr, I found html-vadliate. A cursory glance at the docs as well as the commit history on GitHub and I concluded this was the tool I was looking for.
<a-quick-aside>
I watched the video from FOSDEM 2021 “HTML5 validation with HTML-validate” and it was quite intriguing. Can you spot the validation error here?
<div>
<p>
Contact me at:
<address>
Fred Flinstone
345 Cave Stone Road
</address>
</p>
</div>
If not, watch the video (this part starts at ~4:15). It’s an intriguing look at what the HTML parser does based on the spec.
</a-quick-aside>
Now, I like to think I write pretty good HTML. And I haven’t found any bugs in my blog, which is pretty simple site, so my HTML is probably free of problems — right?
Wrong.
I ran html-validate with the recommended preset and it resulted in over 14,000 errors. That’s right: fourteen thousand.
A lot of those errors appeared to stem from rules like no-trailing-whitespace which, if you look at the rule on html-validate, is really designed for validating source files to help keep a clean git history. Meanwhile I was running the validator on generated files, so the rule seemed less applicable. These are the kinds of rules I could save for another day.
To keep things manageable, I switched to the standard present — which is supposed to be like the Nu HTML Checker, I can live with that as a starting place — and I trimmed down my problems to one thousand five hundred and twenty.
![]()
Now not all of those were errors I wrote. Some were a result of markup generated by other tools, like embedded SVGs.
Others were, however, errors I wrote. In my defense, because I wrote them in one place (e.g. a template) they ended up across many of my HTML files. So a single error in one template resulted in the validator counting it as 300 problems across 300 files. (At this point, I’m just making excuses for myself.)
Anyhow, I figured I would outline the validation errors I encountered as an exercise for myself in saying: you don’t know HTML as well as you thought, Jim.
- I was putting the XML prolog into my HTML documents when embedding SVGs (i.e. the
<?xml version="1.0" encoding="utf-8" ?>thingy). Turns out, that’s a no-no. - I was putting a
checkedattribute on an<option>element instead of theselectedattribute 🤦♂️. - I was nesting a
<div>inside the<output>element, which turns out, is a no-no. - I was using a space character in the subject line of my
mailto:URI. To be honest, I kinda remember thinking that was a no-no when I wrote it, but it worked fine on the devices I tested, so I lazily said “meh, it’s fine.” The validator held me to higher standards and I properly encoded the space as%20. - I was writing
<thead><th>…and forgot to put that in a table row! So I fixed it to:<thead><tr><th>…. - I had a markdown link in a post from like 2014 that was
[][]and resulted in malformed HTML. (I’m kinda surprised the markdown parser didn’t yell at me to be honest…) I fixed it to the proper[]()syntax. - I was writing “<link>” in a markdown file inside an level 2 heading, e.g.
## How to <link> stuff. No backticks. No HTML entities. Just plain text angle brackets. That meant it ended up as<h2>How to <link> stuff</h2>in the HTML, which the validator flagged as a<link>with no correspondinghref🤦♂️. (This actually happened in a few places where I was quoting text from other people and had copy/pasted the angle brackets<and>right into the markdown, resulting in actual elements in the HTML output). I fixed these to be written as<link>in my markdown. (I could’ve used backticks too.) - I had duplicate IDs in one of my documents, which cued me into the fact that I had duplicate links in my reading notes! (I linked to an article in my reading notes in 2012 and then again in 2021 and didn’t know it!)
Turns out, I still make lots of errors when marking up my hypertext documents. The HTML parser is so good at skipping over problems that I never discovered through my testing that these issues existed. That’s a pretty wonderful thing, but I also see how it led me to being lazy.
Having a validator really helped me stay on point in writing my markup. I give the html-validator CLI tool two big thumbs up 👍👍! Maybe I'll get to their recommended presets one day and fix the other ~10,000 problems in my markup.
Now I just need that nice little “W3C Validated HTML” bumpersticker on my site ;)